Applied Interpretability
Exploring how mechanistic interpretability techniques can reveal internal reasoning processes of security-focused language models.
Selected projects and external publications.
Exploring how mechanistic interpretability techniques can reveal internal reasoning processes of security-focused language models.
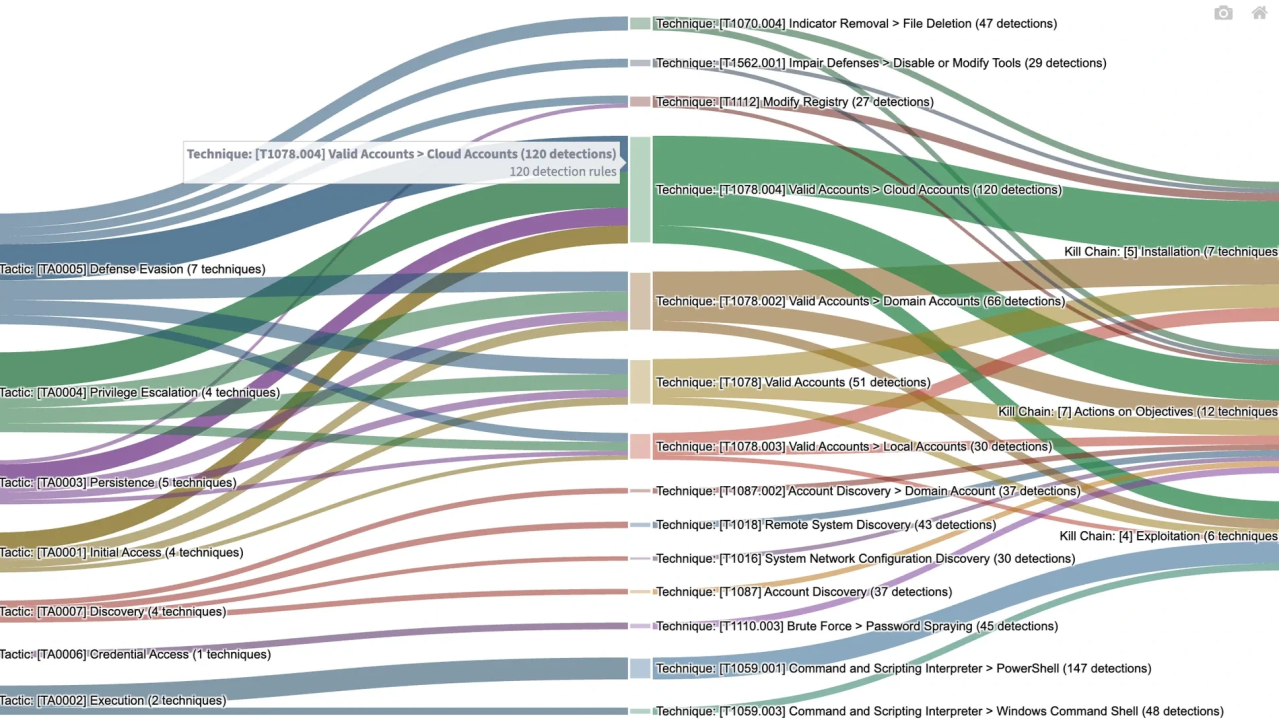
A framework for transforming traditional detection engineering logic into LLM-driven reasoning systems.

Research exploring how LLMs can be guided with security context to accelerate threat detection and response workflows.

Proposing approaches to quantify emerging cybersecurity risks associated with AI misuse.